

度加创作工具
度加创作工具-度加剪辑官网文案成片、文章成片、素材匹配、一键
将多张静态图片快速合成为动态视频,适用于电商、社交媒体等多种场景。
绘蛙推出多图成片功能,这是一项借助人工智能技术的视频生成工具,旨在帮助用户迅速地将静态图片转化为引人入胜的动态视频,广泛适用于电子商务与社交媒体等多种应用场景。该功能利用AI技术,实现了图片的智能拼接以及流畅的效果,让用户无需掌握复杂的专业技能,便能轻松创作出高质量的视频内容。
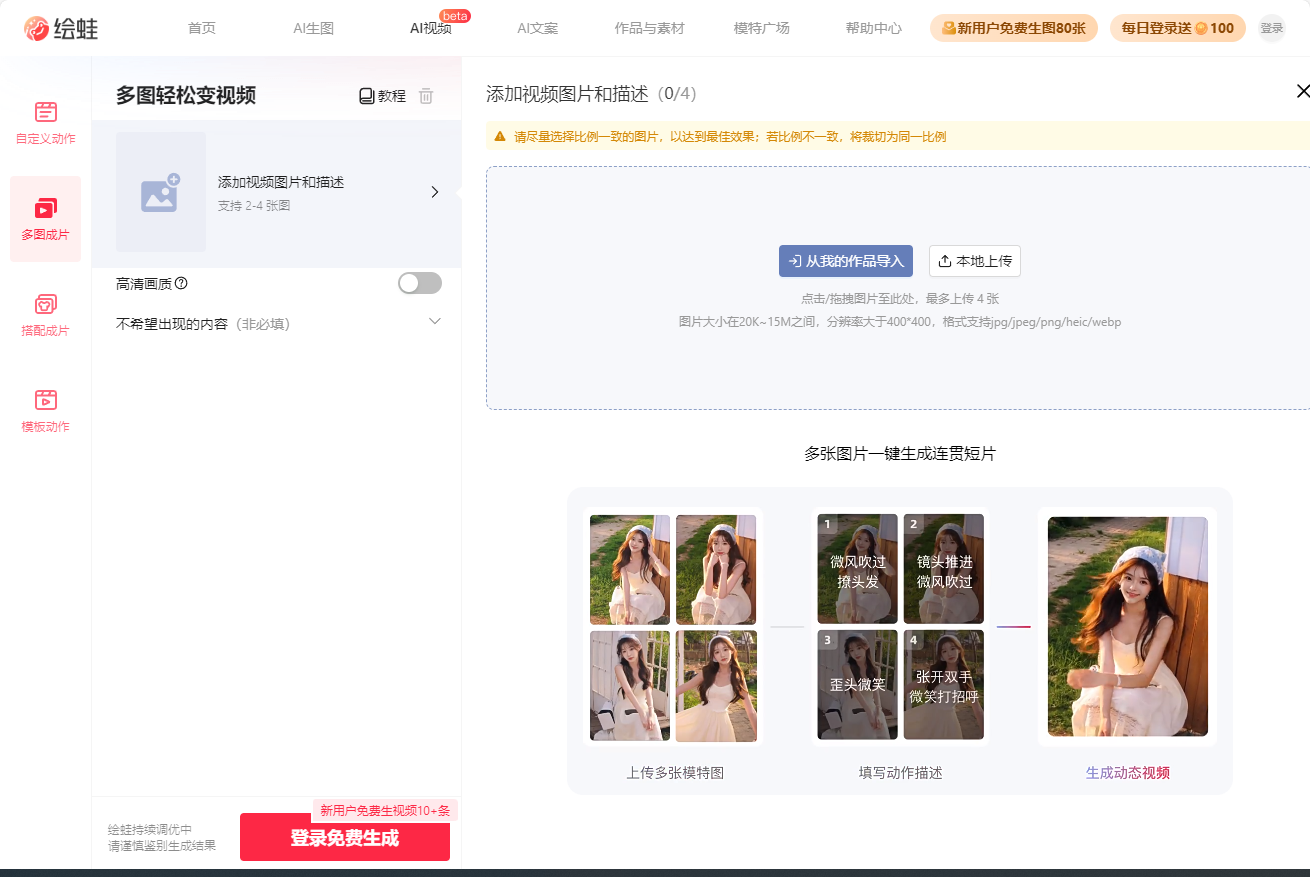
绘蛙多图成片功能凭借先进的AI技术,简化了视频制作的复杂流程,为广大用户提供了一种高效且经济的视频创作解决方案。
https://www.ihuiwa.com/workspace/ai-video/multi-img
AiHome小编发现绘蛙-多图成片网站非常受用户欢迎,请访问绘蛙-多图成片网址入口试用。
本站智能信息网提供的绘蛙都来源于网络,不保证外部链接的准确性和完整性,同时,对于该外部链接的指向,不由智能信息网实际控制,在2025年4月26日 下午10:02收录时,该网页上的内容,都属于合规合法,后期网页的内容如出现违规,可以直接联系网站管理员进行删除,智能信息网不承担任何责任。

 百度热点
百度热点