
 豆包官网入口
豆包官网入口 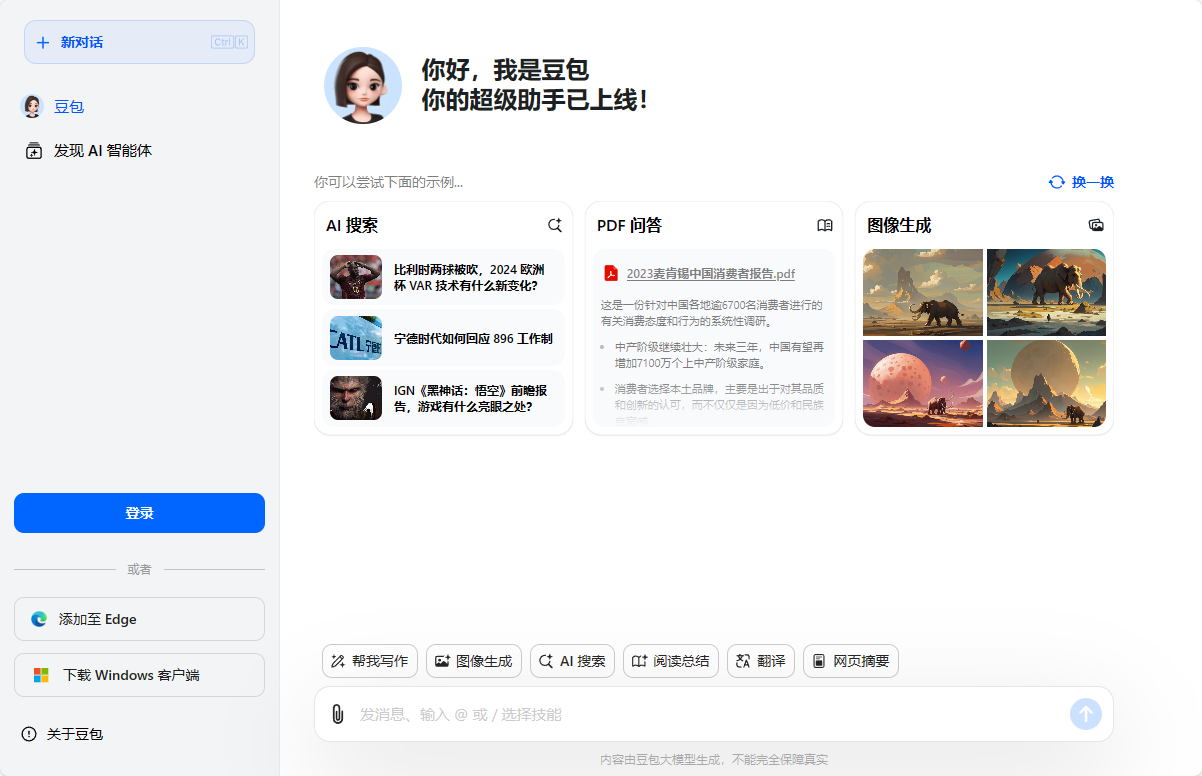

Grok
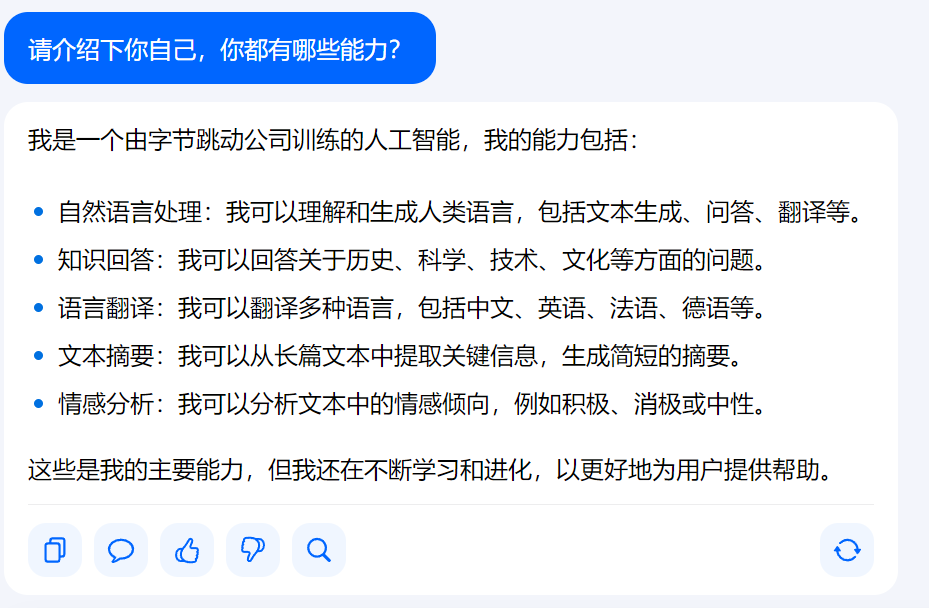
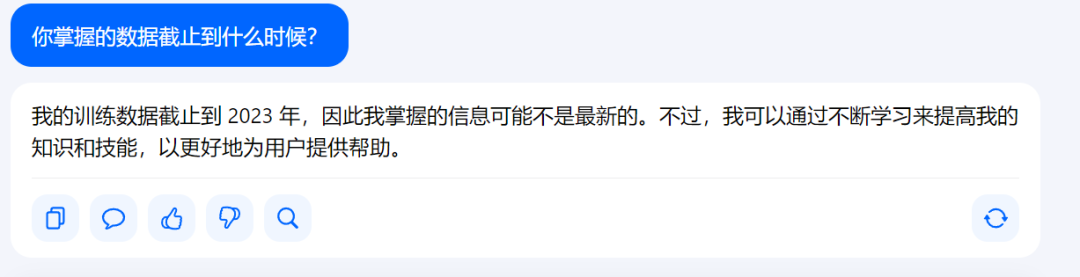
Grok是什么Grok 是马斯克旗下的xAI公司最新推出的多功能人工智能助手,一个与 ChatGPT 类似的聊天机器人,关键的区别之处在于 Grok 可以实时访问 𝕏(原Twitter)数据,可以为用户提供最新且独特的信息。通过自然语言处理技术为用户提供智能对话、图像生成和实时信息查询等功能。Grok的主要功能智能对话与问答:Grok 能理解用户的自然语言输入,生成流畅、智能的回答。支持多种类型的对话,包括日常闲聊、问题解答和复杂推理任务。图像生成与分析:Grok 支持根据文本描述生成高质量图像,能分析用户上传的图片,提供详细的描述和分析。实时信息查询:Grok 可以实时访问 X(前 Twitter)平台的数据,为用户提供最新的动态和趋势信息。在回答时事问题时更具时效性。文档处理与分析:用户可以上传文档(如研究报告、文章等),Grok 能快速解析并提供总结、分析或回答相关问题。编程与代码辅助:Grok 支持编写代码、调试程序,帮助用户解决编程问题。多模态交互:Grok 提供多种交互模式,包括自动模式、可视化模式、搜索模式和仅模型模式,用户可以根据需求灵活切换。Grok的官网地址官网地址:x.ai/grok如何使用Grok平台支持:Grok 可通过网页版、iOS 和 Android 应用使用。网页版无需注册 X 账号即可体验。免费版限制:免费用户每两小时可发送 10 条文本提示,每天最多分析 3 张图片。Grok的应用场景内容创作与编辑:Grok 可以帮助创作者生成文章、故事、视频脚本、广告文案等内容,显著提升创作效率。支持根据文本描述生成高质量图像,为社交媒体帖文或创意项目提供配图。教育领域:Grok 可以作为学生的学习伙伴,根据学生的学习进度和兴趣提供个性化的学习计划和辅导。可以为教师提供教学资源和课程设计建议,帮助提升教学效率。金融与风险管理:在金融领域,Grok 能分析市场趋势、财务报表等数据,帮助投资者做出科学的投资决策。可以用于风险预测,帮助金融机构识别潜在风险并制定应对措施。医疗健康:Grok 可以辅助医生进行疾病诊断和治疗方案制定,通过分析患者的病历、检查报告和基因数据提供专业建议。用于医疗影像分析,帮助医生更准确地识别病变。客户服务:Grok 能处理海量客户咨询,提供快速、准确的解答,显著提升客户服务效率。可以集成到企业的在线客服系统中,帮助企业降低人力成本并提高客户满意度。市场营销:Grok 可以分析客户反馈,生成市场趋势报告,帮助营销人员制定实时的营销策略。Grok的特色与优势回答任何问题,解决用户疑问并生成创造性的文本格式,如诗歌、代码、脚本和邮件独特个性,相比于其他的聊天机器人,Grok的回复更具“幽默感”与 𝕏 (原Twitter)平台对接,可实时获取该社交平台最新状态充当强大的研究助手,帮助用户快速访问相关信息、处理数据并提出新想法

